How deepbots works
Here you can find a high-level explanation on how the framework is structured and how it actually works.
Read on if you want to dig deeper into how and why deepbots works the way it does. If you want a quick start, visit our beginner tutorial and if you want to see deepbots in action, visit deepworlds!
Overview
First of all let’s set up a simple glossary:
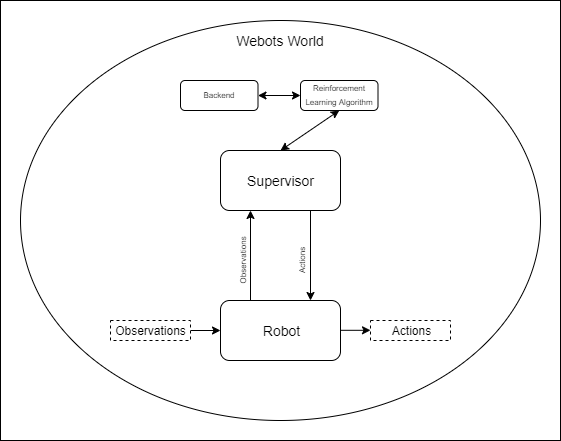
World: Webots uses a tree structure to represent the different entities in the scene. The World is the root entity which contains all the Webots entities/nodes. For example, the world contains the Supervisor and Robot entities as well as other objects which might be included in the scene.
Supervisor: The Supervisor is an entity which has access to all other entities of the world, which can have a physical presence or not. For example, the Supervisor knows the exact position of all the entities of the world and can manipulate them.
Supervisor Controller: The Supervisor Controller is a python script which is responsible for the Supervisor. For example, in the Supervisor Controller script the distance between two entities in the world can be calculated or entities can be moved around, etc.
Robot: The Robot is an entity that represents a robot in the world. It might have sensors and other active components, like motors, etc., as child entities. For example, epuck and TIAGo are robots.
Robot Controller: The Robot Controller is a python script which is responsible for the Robot’s movement and sensors. With the Robot Controller it is possible to observe the world and act accordingly by for example turning the Robot’s motors.
Environment: The Environment is the interface as described by The Environment must have the following methods:
get_observations(): Return the observations of the robot. For example, metrics from sensors, a camera image, etc.
step(action): In each timestep, the agent chooses an action and the environment returns the observation, the reward and the state of the problem (done or not).
get_reward(action): The reward the agent receives as a result of their action, based on which it gets trained.
is_done(): Whether it’s time to reset the environment. Most (but not all) tasks are divided up into well-defined episodes, and done being True indicates the episode has terminated. For example, if a robot has to reach a goal, then the done condition might happen when the robot “touches” the goal, or when it collides with an obstacle.
reset(): Used to reset the world to the initial state and start a new training episode.
In order to set up a task in deepbots it is necessary to understand the intention of the gym environment. According to gym’s documentation, the framework follows the classic “agent-environment loop”. “Each timestep, the agent chooses an action, and the environment returns an observation and a reward. The process gets started by calling reset(), which returns an initial observation.”

Deepbots follows this exact agent-environment loop with the only difference
being that the agent, which is responsible to choose an action, runs on the
Supervisor and the observations are acquired by the Robot. The goal of
deepbots is to bridge the gap between the gym environment and the Webots
robot simulator. More specifically,
deepbots.supervisor.DeepbotsSupervisorEnv() is the main class that
provides the interface which is used by the Reinforcement Learning algorithms
and follows gym’s environment logic. Deepbots provides different levels of
abstraction to be used according to the user’s needs. Moreover, the framework
provides different wrappers for additional functionalities.
Deepbots also provides a default implementation of the reset() method, leveraging Webots’ built-in simulation reset functions, removing the need for the user to implement reset procedures for simpler use-cases. It is always possible to override this method and implement any custom reset procedure as needed by the use-case.
All-in-all to set up your gym environment you have to create a class that inherits one of deepbots’ classes and implement the methods that are specific to your use-case and deepbots will handle interfacing the environment with Webots. As your familiarity and/or needs grow, you can override deepbots’ methods to alter functionality or inherit from classes higher up in the hierarchy.
Deepbots targets users that are unfamiliar with either Webots or gym environments or both. If you have a strong understanding of both, you can forgo using deepbots altogether, but if you chose otherwise, it can make your code more modular and clean.
The two deepbots schemes
Deepbots includes two schemes to set up your RL environment, the emitter-receiver scheme which separates the Robot and the Supervisor in two different entities and the Robot-Supevisor scheme which combines them into one entity. Both are described below.
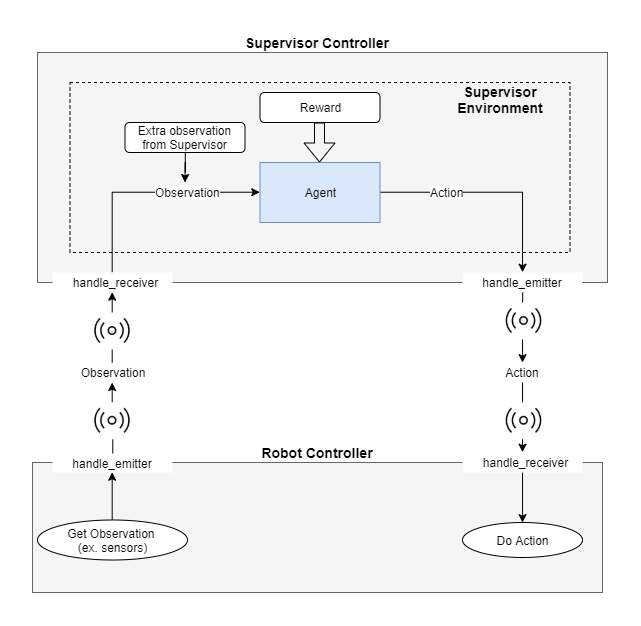
Emitter - receiver scheme
In this scheme the Robot and the Supervisor are separated into two entities within the World. Communication between the two nodes is needed so the Supervisor can send the agent’s actions to the Robot and for the Robot to send back its observations, and can be achieved in various ways. The main way communication between the Supervisor and the Robot is achieved, is via emitters and receivers. By separating the Supervisor from the Robot, deepbots can fit a variety of use-cases, e.g. multiple Robots collecting experience and a Supervisor controlling them with a single agent. The way Webots implements emitter/receiver communication requires messages to be packed and unpacked, which introduces an overhead that becomes prohibiting in use-cases where the observations are high-dimensional or long, such as camera images. Deepbots provides another scheme that combines the Supervisor and the Robot into one controller and circumvents that issue, while being less flexible, which is discussed later.
On one hand, the emitter is an entity which is provided by Webots, that broadcasts messages to the world. On the other hand, the receiver is an entity that is used to receive messages from the World. Consequently, the agent-environment loop is transformed accordingly. Firstly, the Robot uses its sensors to retrieve the observation from the World and in turn uses its emitter component to broadcast it. Secondly, the Supervisor receives the observation via its receiver component and in turn, the agent uses it to choose an action. The Supervisor uses its emitter to broadcast the action, which the Robot receives with its receiver, closing the loop.
It should be noted that the observation the agent uses might be extended in the Supervisor with additional values that the Robot might not have access to. For example, an observation might include LiDAR sensors values taken from the Robot, but also the Euclidean distance between the Robot and an object. As expected, the Robot cannot calculate the Euclidean distance, but the Supervisor can, because it has access to all entities in the World and their positions.
You can take a look at the Supervisor and Robot classes implementations for
this scheme in deepbots.supervisor.EmitterReceiverSupervisorEnv()/
deepbots.supervisor.CSVSupervisorEnv() and
deepbots.robots.EmitterReceiverRobot()/deepbots.robots.CSVRobot()
respectively.
You can follow the emitter-receiver scheme tutorial to get started and work your way up from there.
Combined Robot-Supervisor scheme
As mentioned earlier, in use-cases where the observation transmitted between the Robot and the Supervisor is high-dimensional or long, e.g. high resolution images taken from a camera, a significant overhead is introduced. This is circumvented by inheriting and implementing the partially abstract RobotSupervisorEnv that combines the Robot Controller and the Supervisor Controller into one, forgoing all emitter/receiver communication. This controller runs on the Robot, but requires Supervisor privileges and is limited to one Robot - one Supervisor.
You can take a look at the combined Robot - Supervisor environment class in
deepbots.supervisor.RobotSupervisorEnv(), which acts both as the
Robot Controller/Supervisor Controller and the Environment the RL agent
interacts with.
You can follow the robot-supervisor scheme tutorial to get started and work your way up from there. We recommend this scheme/tutorial to get started with deepbots.
Abstraction Levels
The deepbots framework has been created mostly for educational and research purposes. The aim of the framework is to enable people to use Reinforcement Learning in Webots. More specifically, we can consider deepbots as a wrapper of Webots exposing a gym-style interface. For this reason there are multiple levels of abstraction via a family of classes. For example, a user can choose if they want to use a CSV emitter/receiver or if they want to make a communication implementation from scratch. In the top level of the abstraction hierarchy is the DeepbotsSupervisorEnv class which is the main gym interface. Below that level there are partially implemented classes with common functionality. These implementations aim to hide the communication between the Supervisor and the Robot and other various functions needed by the simulator for a gym environment to work, as described in the two different schemes earlier. Feel free to explore the documentation and the full family of classes and to create and customize your own, inheriting from whichever deepbots class you choose according to your needs.